Written by Roy Jamil, Training Engineer at Ac6
Introduction
We are happy to announce our new course “Real-time programming using Zephyr”
This course covers topics that let you get started with Zephyr and learn advanced multithreading.
Course objectives:
- Learn how to develop, configure, debug and trace Zephyr applications
- Discover the real time multitasking concept
- Understand Real Time constraints like determinism, pre-emption, interrupts …
- Understand Zephyr Kernel Services
- Learn communication and synchronization mechanisms
- Interactions with processor architecture features
- Understand Zephyr memory management and data structures
- Get runtime statistics, and display visual trace diagnostics using Tracealyzer
Ac6 provides hardware and software training, covering all the fields of embedded systems either online, using the most advanced online training platforms, at Ac6 premises, located near Paris La Défense or at customer’s premise all over the world.
Structure and Content of the course
We will start by getting an overview of microcontrollers (Cortex-M) resources that are used by Zephyr Kernel. Then we will investigate features that impact the stack memory on one side and technologies that help to detect stack overflow on the other side. The next topic will cover real time, determinism, and multithreading concepts and the available solutions for software architecture application flow.
Then we will dive into the Zephyr ecosystem and list the most important supported features which will show you why Zephyr might be a perfect fit for your application.
After learning how to install and use Zephyr either with or without “west”, we will discover all the possible approaches to configure it and see what the recommended methods are.
Two points on Zephyr might need custom configuration:
- Device properties using a device tree. A device tree source file (dts) describes the platform. Custom configurations can be added by creating device tree overlays.
Or
- Build configuration based on Kconfig.
Kconfig can be used to enable or configure options, to explore the available options and make changes. Zephyr provides tools to edit the options (menuconfig and guiconfig), but these changes are only temporary, different methods are shown to make these changes permanent, like creating an overlay config.
Zephyr can be used without threads, and we will start by presenting the features that are expected to work in this case, like GPIO management (for example toggle LEDs), random number generation options and more.
Data structures that are heavily used in embedded systems are discussed in depth, such as linked lists (singly or doubly) or ring buffers. You will learn the best practices, how and when they should be used, in addition to understanding container_of functionality.
Secondly, we will look at the Zephyr scheduler, the different scheduling strategies, and time slicing, including the different internal kernel implementations for ready queues.
You will learn what is a Zephyr thread, its states, and its components, how to put a thread to sleep, suspend it and how to change its priority.
Lab example:
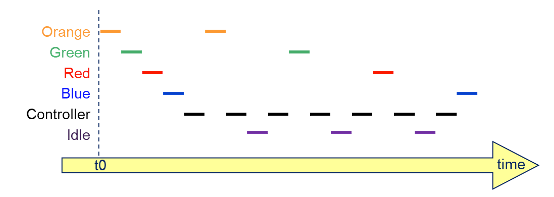
Create four periodic threads where each toggles a different LED, they are managed by a controller thread. After creating this application, a config overlay should be created to enable tracing.
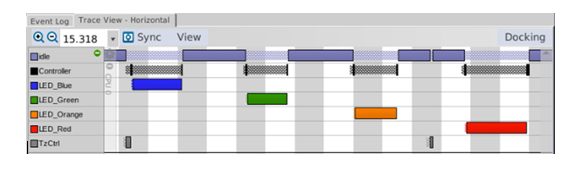
This is the expected visual trace as shown by Tracealyzer tool from Percepio, you can see that each LED thread is executing after being resumed by the controller thread, meanwhile the controller stays in ready state.
In addition to thread creation and manipulation, we will explore memory management options for Zephyr, learn how to manage static or dynamic memory and where each block is exactly placed. Moreover, we will help you to understand the specificities of each dynamic memory allocator available in Zephyr, how to use it and the best practices. Then we will analyze threads memory usage, what can be modified and how to detect stack overflow using hardware or software features while showing their impact on the performance.
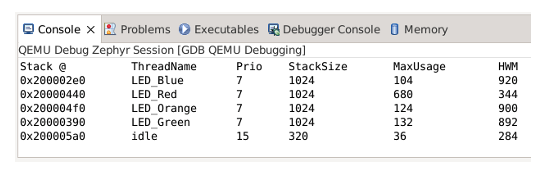
In this example, we used Zephyr features to create functions that display stack memory information of the available threads in the system.
On the resource management side, we will explain how mutexes work and why they are needed and showing a lot of examples. You will discover why priority inversion is a problem and what is priority inheritance. Furthermore, we will show what are the side effects of mutexes like deadlocks and how to avoid them.
Other resource management methods are discussed, like gatekeeper threads and lock free data structures that are based on the atomic Zephyr functionality. Masking interrupts and spinlocks are also presented with a lot of tips on how and when they should be used.
On the synchronization and communication side, all available synchronization primitives are presented in detail, like semaphores, events, condition variables… Exercises focus on using the mechanisms available to solve traditional problems: Readers-writers, producer-consumer where each exercise includes a detailed explanation and a diagram which helps understand how the algorithm works. Furthermore, all data passing mechanisms are presented and how they should be used for Thread-to-Thread, Thread-to-Interrupt, or Interrupt-to-Thread communication.

Finally, interrupt and power management are presented. We will start by explaining why we should differ execution from an interrupt to a thread and what are the different methods to do this. Additionally, we will see what the proposed strategies by Zephyr are. At the end, the power management feature is discussed alongside ways to reduce the system power consumption.
Other optional topics can be added upon request, like device driver model and writing Zephyr drivers, symmetric and asymmetric multiprocessing, secure boot, trusted firmware, MCUboot, IP stack.
For more details, visit our website by clicking here.