This blog originally ran on the Antmicro website. For more Zephyr development tips and articles, please visit their blog.
Neural networks are a powerful tool for processing noisy and unstructured sensor data like camera frames, accelerometer or biometric readings, which makes them perfect for preprocessing or decision making on edge devices, where such sensors are usually placed. However, running neural networks on the edge faces extreme memory constraints and computational limitations which our open source framework called Kenning helps mitigate by letting you combine various optimization algorithms, as well as deep neural compilers.
So far, Kenning offered runtimes for Python running on Linux for high-performance edge devices like the Jetson AGX Orin and for bare metal applications such as the IREE-based software for the Kelvin RISC-V accelerator (used in the Open Se Cura project led by Google). In one of our previous blog notes, we demonstrated the latter running in our Renode simulation framework, enabling pre-silicon AI HW-SW co-design.
The next step for the project was to implement a more mature C-based library encapsulating runtimes for Kenning and an evaluation application capable of evaluating model, runtime and hardware performance on various SoCs and boards. Zephyr RTOS, which we extensively use and contribute to in our work as Platinum members of the project was the obvious choice here, as we can take advantage of its open source SDK, Hardware Abstraction Layers and the project’s build flow, portable across an impressive > 500 boards. (For a full list, including > 400 boards with demos in Renode, you can see our Zephyr Dashboard).
In this note we introduce Zephyr runtime for Kenning – a Zephyr library with a unified API for various microcontroller runtimes for neural networks, as well as an application for evaluating models on-device (also in simulation) with Kenning.
Kenning Zephyr runtime library
The first element of the Kenning Zephyr runtime project is a Zephyr library which provides a unified API for various neural network inference frameworks, including methods for loading models, passing inputs, running inference and returning outputs. This enables developers to use any inference implementation that works best for their application, model and board regardless of underlying frameworks, without changes to the application code.
In addition to exposing an API for the runtime, the library also optionally provides methods and calls for interfacing with an instance of Kenning running on a developer’s desktop PC via the UART protocol used in the application itself. This significantly reduces iteration time for model optimization and development, because instead of recompiling the application with a new model, we can just run another optimization, upload the model to the device and run another benchmark, without reflashing or recompilation.
Kenning Zephyr runtime evaluation application
One of the main features of Kenning is the ability to connect to a target device and benchmark a model. In the Python library, we have a kenning server subcommand that runs on a target device and enables the desktop PC to do the following:
- Send the model to the device and load it
- Send input data to the device
- Request inference of the input data on device
- Request predictions from the device
- Request additional hardware measurements collected during inference (memory usage, CPU utilization and more).
Currently, the communication between developer’s PC and target device uses such protocols as TCP or UART.
In the case of the Zephyr implementation, we have a dedicated app for communicating with Kenning on host devices using a specified protocol to evaluate models that acts just like the kenning server command described above. Currently, the project supports communication via UART, but switching to a different protocol is a matter of implementing several functions to initialize communication for sending and receiving bytes of data as described in the tutorial in the project’s README.
Jumping from simulation to hardware with Kenning
Kenning is not limited to physical hardware and can be used for testing models and runtimes on hardware in Renode simulation. This means that with Zephyr runtime for Kenning, we can test and optimize models without hardware in the loop, for instance:
- during development of libraries running inference on a device
- in a CI system
- during hardware development
- to verify a given model’s function and performance on a given hardware platform before acquiring it
- when developing a new AI accelerator, to check how it performs with existing models, inference libraries or our new inference library dedicated for the accelerator; with Renode we can simulate the accelerator (like in the Open Se Cura project described in a previous blog note) or even co-simulate the design using Verilator.
Since Renode is software agnostic, switching between execution on hardware and in simulation is quite straightforward, as in both scenarios we execute the exact same binary, use (in this case, a simulated) UART for communication and evaluate the model the same way.
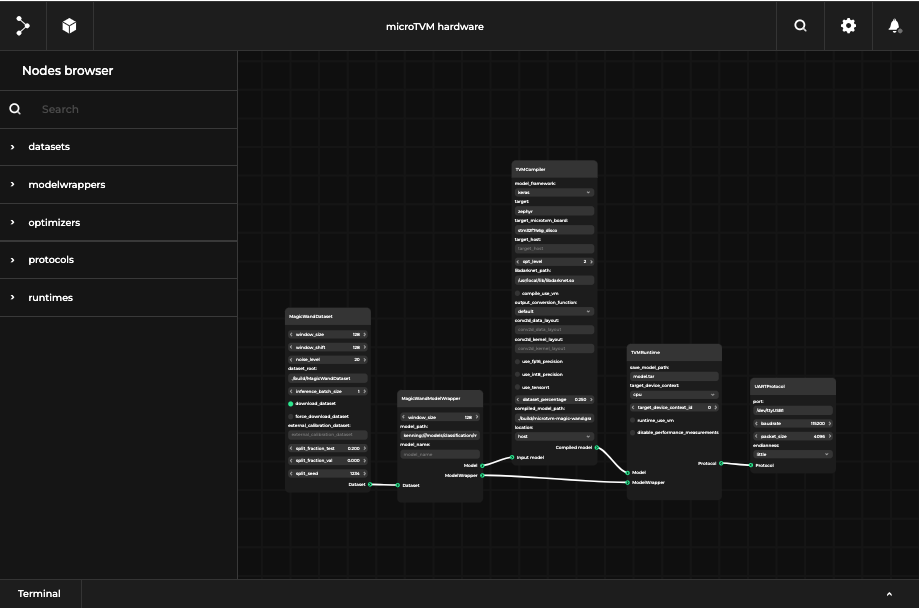
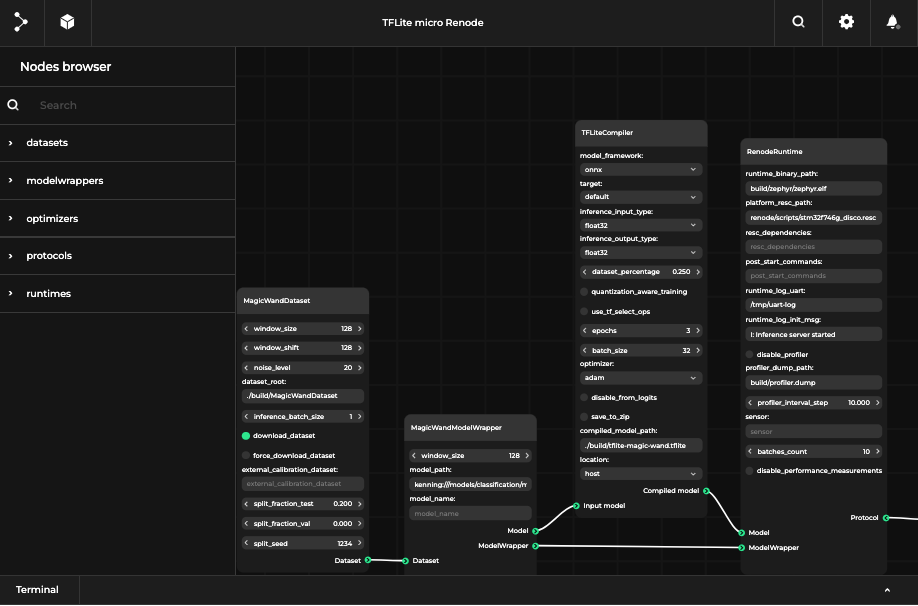
Below you can see interactive diagrams (on desktop only) prepared in our Pipeline Manager tool depicting optimization scenarios running in Kenning on physical hardware and in Renode simulation.
TVM-based scenario running on physical hardware:
TFLite-based scenario running on hardware simulated in Renode:
Creating a simple application with Kenning Zephyr runtime
The Kenning Zephyr runtime also includes a basic demo_app application which does not communicate with Kenning but instead includes a hard-coded model and several batches of input data. After booting, it loads the model and performs inference on the provided input and prints the model output on the UART console. The result is visible below:
 Benchmark your AI runtimes, models and hardware reliably with Kenning, Zephyr and Renode
Benchmark your AI runtimes, models and hardware reliably with Kenning, Zephyr and Renode
Introduction of the Kenning runtime to the Zephyr ecosystem allows us to enable unified support of various runtimes for neural networks on edge devices and a simulation-enhanced flow for their benchmarking and optimization. An open solution like this can prove useful for several use cases, e.g.:
- Developers of AI runtimes who want to test and benchmark the operation and compatibility of their solutions on different targets
- Developers of ML models intended for resource-constrained devices
- Semiconductor / product development companies who want to build and test their solutions in the context of edge AI.
In order to utilize the Zephyr runtime for Kenning for such benchmarking and comparison, Antmicro assists its customers in implementing functions required for loading models and data inference in case of new runtimes, implementing helper functions for preparing I/O and loading models to the optimization pipeline in case of new models, as well as customization of the Zephyr app configuration file to utilize the runtime. Should your hardware not be supported in Zephyr, we will gladly assist you in porting to such platforms.
If you are interested in taking advantage of the open source development flow offered by Kenning, Zephyr and Renode for building and testing your edge AI solutions in a replicable, structured methodology, feel free to reach out to us to discuss your needs at contact@antmicro.com.